![[アップデート]Apache Iceberg形式のテーブルデータに最適化されたストレージAmazon S3 Tablesが発表されました](https://images.ctfassets.net/ct0aopd36mqt/3nibOl2sZ0LKJueI0FHFi5/14de7bd294f7916a28b789105c60d450/reinvent-2024-newservice-jp.jpg?w=3840&fm=webp)
[アップデート]Apache Iceberg形式のテーブルデータに最適化されたストレージAmazon S3 Tablesが発表されました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部インテグレーション部機械学習チーム・新納(にいの)です。
日本時間2024年12月4日、re:Invent 2024のキーノートにてAmazon S3 Tablesが発表されました。

what's newでも以下の通り発表されています。
Amazon S3 Tablesとは
Apache Iceberg形式のテーブルデータに最適化されたストレージサービスで、Amazon Athena、Amazon EMR、Apache Sparkなどのクエリエンジンからデータをクエリ可能です。従来のストレージと比べて、最大3倍のクエリ性能と10倍のトランザクション処理が可能となりました。
S3 Tablesは以下から構成されます。
- Table bucket:Icebergテーブルを保存
- Namespace:テーブルを論理的にグループ化し、アクセス管理を容易にする
- Table:構造化データで構成されるテーブルで、コンパクション、スナップショット管理、孤立ファイルの削除などのメンテナンスを自動で実行する
現在、us-east-1(バージニア), us-east-2(オハイオ), and us-west-2(オレゴン) リージョンで利用可能ですが、以下AWSのアナリティクスサービスとS3 Tableの統合はプレビューのステータスです。
- Amazon Athena
- Amazon Redshift
- Amazon EMR
- Amazon QuickSight
- Amazon Data Firehose
実際に使ってみる
マネジメントコンソールからTable Bucket作成
実際にS3 Tableの構成要素となるTable bucket、Namespace、Tableを作成してみましょう。AWSマネジメントコンソールでS3の画面を見ると、Table bucketsのメニューがあります。
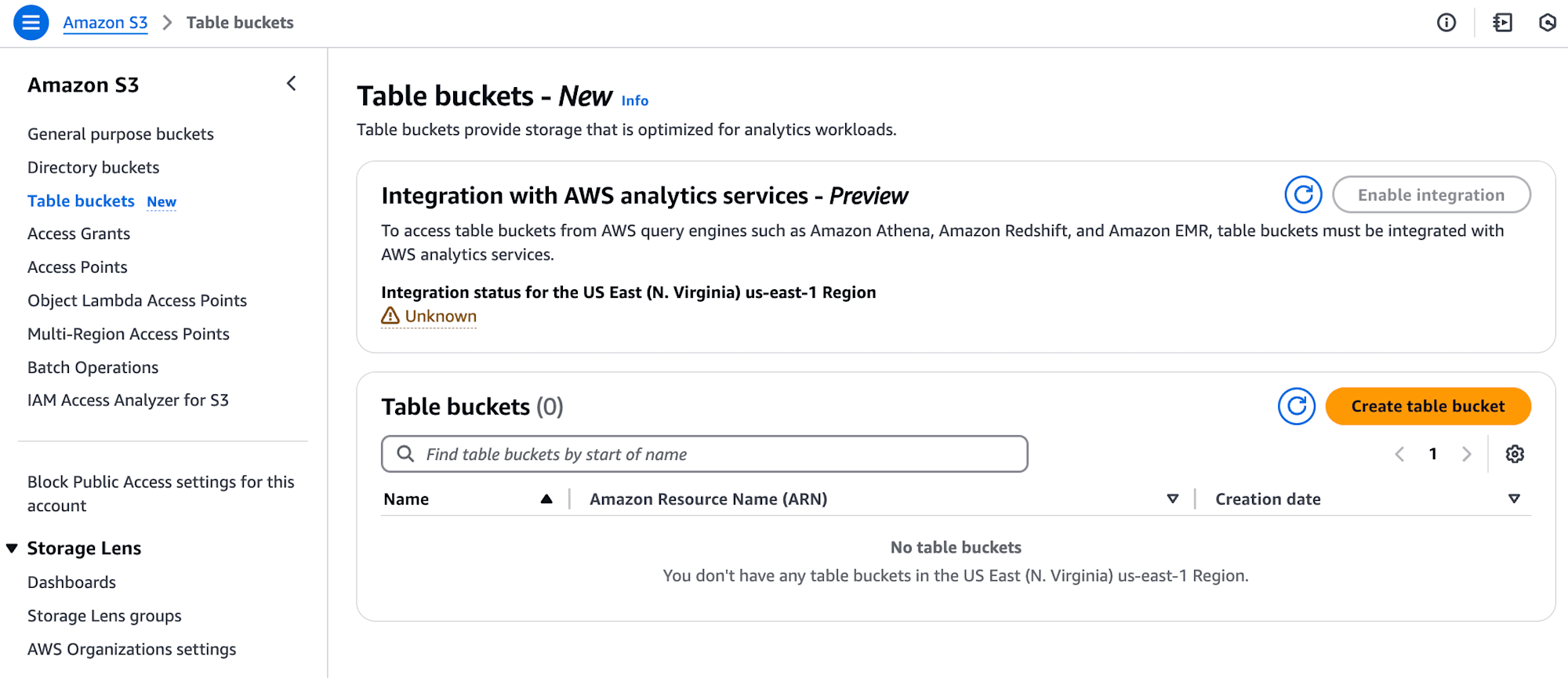
Table bucket nameを入力して作成します。Enable integrationを有効にするとGlueやAthenaなどのアナリティクス系サービスからテーブルを参照できるようになります(現在はプレビュー機能)。
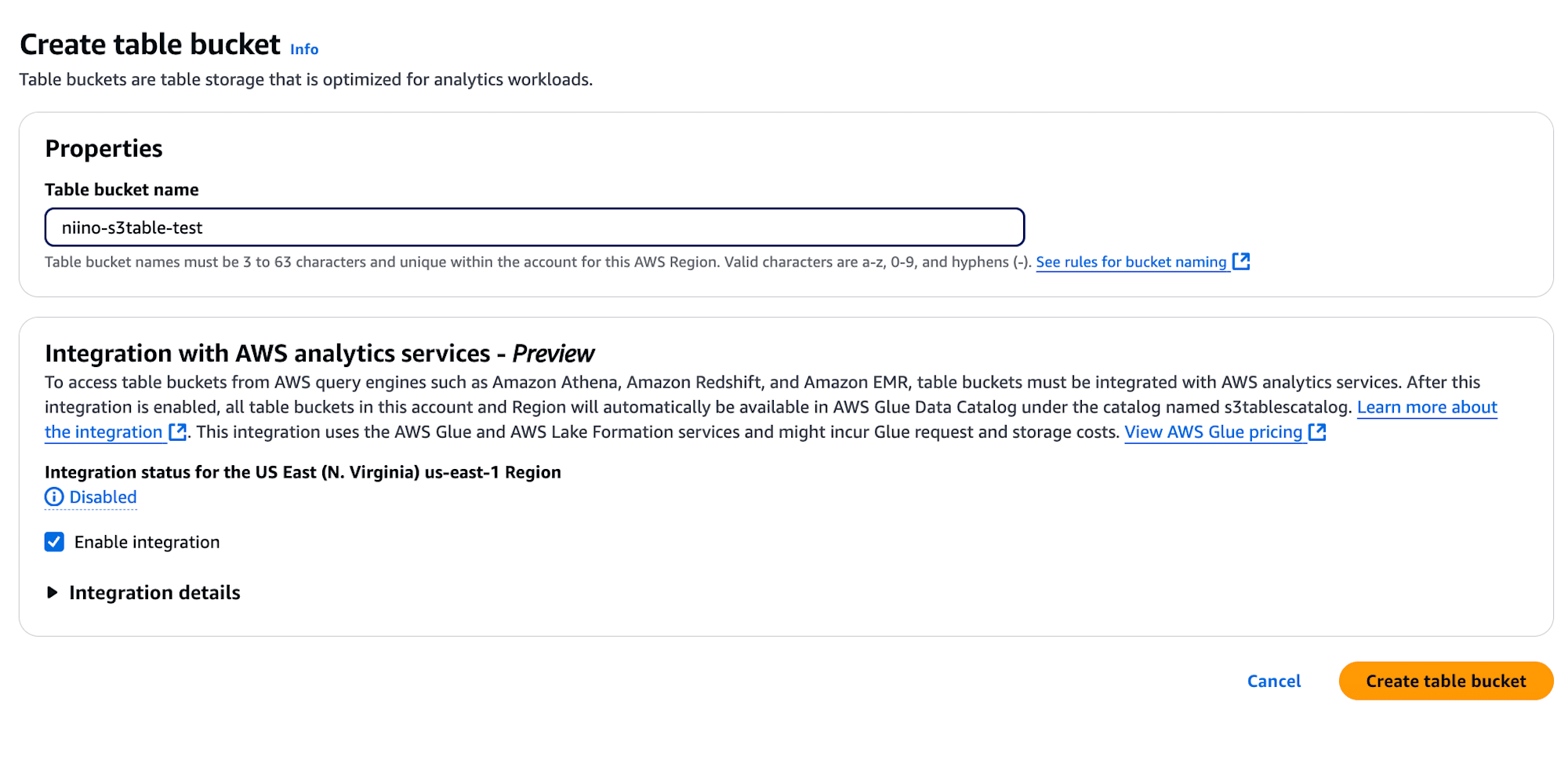
SparkシェルでNamespaceとTableを作成
マネジメントコンソール上ではテーブルの作成、変更、削除は、Amazon EMRを利用しましょうとの記載がありますが、今回は簡単に検証するため、CloudShellにSparkシェルをインストールしてから利用しました。インストール方法は後述のおまけに記載しています。
以下のオプションをつけてSpark Shellを起動します。
spark-shell \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3,software.amazon.awssdk:s3tables:2.29.26,software.amazon.awssdk:s3:2.29.26,software.amazon.awssdk:sts:2.29.26,software.amazon.awssdk:kms:2.29.26,software.amazon.awssdk:dynamodb:2.29.26,software.amazon.awssdk:kms:2.29.26,software.amazon.awssdk:glue:2.29.26 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=<Table bucketのARN> \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.driver.extraJavaOptions="-Djava.security.manager=allow"
まずは任意の名前でNamespaceを作成します。
spark.sql("create namespace if not exists s3tablesbucket.<任意のNamespace名>")
SHOWコマンドを実行すると作成したNamespaceが確認可能です。
scala> spark.sql("SHOW NAMESPACES IN s3tablescatalog").show()
+---------------+
| namespace|
+---------------+
|niino_namespace|
+---------------+
次にテーブルを作成します。売上データが蓄積されていくことを想定し、商品名、数量、タイムスタンプをカラムとして持つテーブルを作成しました。
spark.sql("create table if not exists s3tablesbucket.niino_namespace.sales ( product string, amount int, timestamp timestamp) using iceberg ")
INSERTクエリで仮のデータを挿入します。
spark.sql("""
INSERT INTO s3tablesbucket.niino_namespace.sales
VALUES
('Laptop', 1200, timestamp '2023-12-01 10:30:00'),
('Smartphone', 800, timestamp '2023-12-01 11:15:00'),
('Headphones', 150, timestamp '2023-12-02 09:45:00'),
('Monitor', 350, timestamp '2023-12-02 14:20:00'),
('Keyboard', 80, timestamp '2023-12-03 16:30:00'),
('Mouse', 45, timestamp '2023-12-03 16:35:00'),
('Tablet', 500, timestamp '2023-12-04 13:15:00'),
('Printer', 250, timestamp '2023-12-04 15:45:00'),
('Speaker', 120, timestamp '2023-12-05 10:20:00'),
('Webcam', 90, timestamp '2023-12-05 11:30:00')
""")
SELECTするとINSERTしたレコードを確認できました。
scala> spark.sql("select * from s3tablesbucket.niino_namespace.sales").show()
+----------+------+-------------------+
| product|amount| timestamp|
+----------+------+-------------------+
| Laptop| 1200|2023-12-01 10:30:00|
|Smartphone| 800|2023-12-01 11:15:00|
|Headphones| 150|2023-12-02 09:45:00|
| Monitor| 350|2023-12-02 14:20:00|
| Keyboard| 80|2023-12-03 16:30:00|
(中略)
+----------+------+-------------------+
マネジメントコンソールから確認すると、作成したテーブルのNamespaceとARNが表示されています。
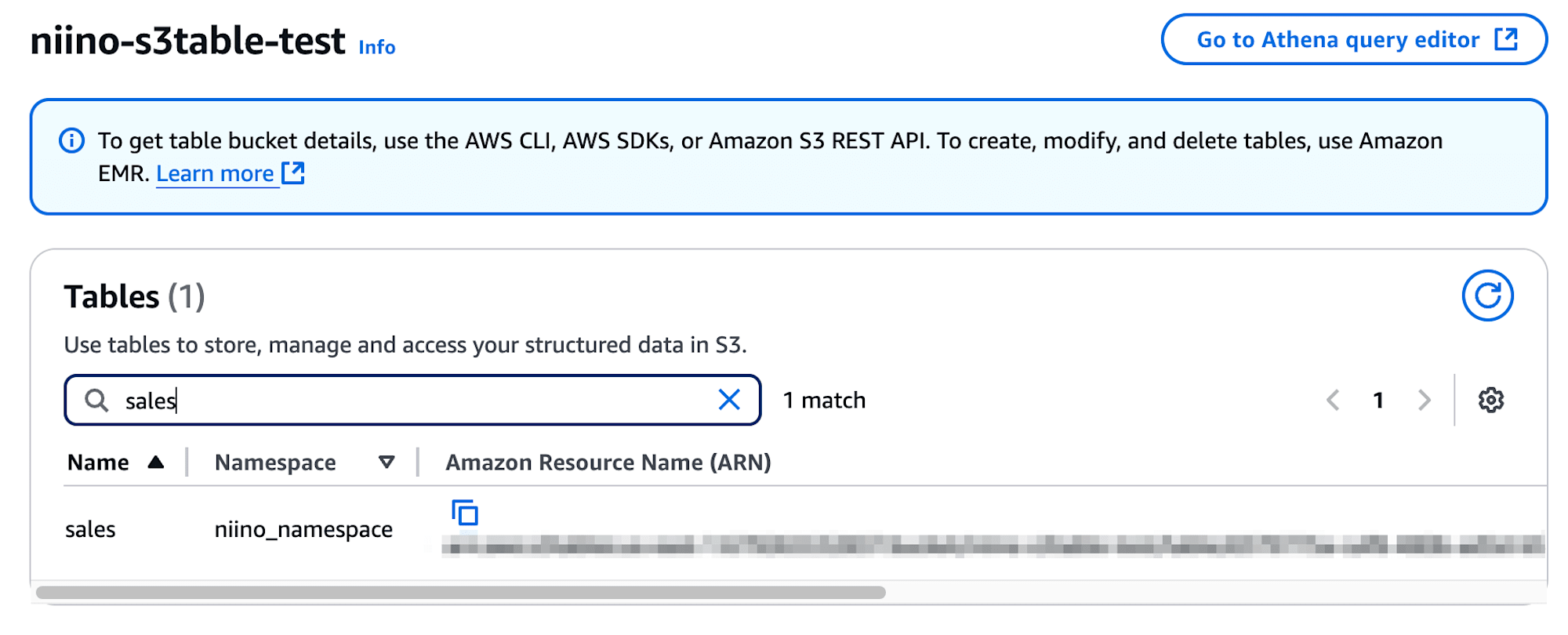
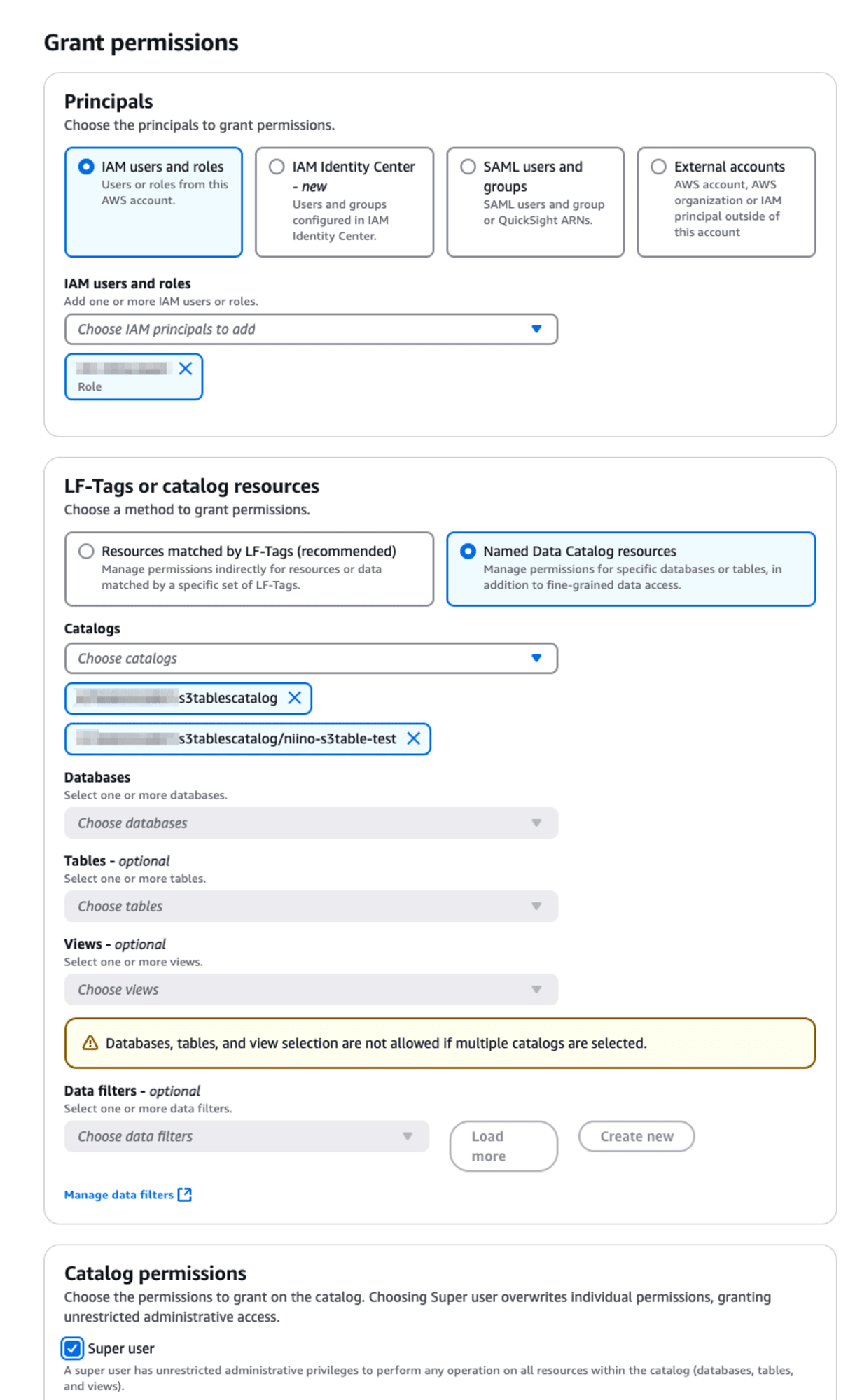
Amazon Athenaをはじめとしたアナリティクス系サービスとの統合はプレビュー状態ですが、クエリできるか確認してみましょう。マネジメントコンソールからLake Formationへアクセスし、Catalogsからs3tablescatalogにアクセスします。
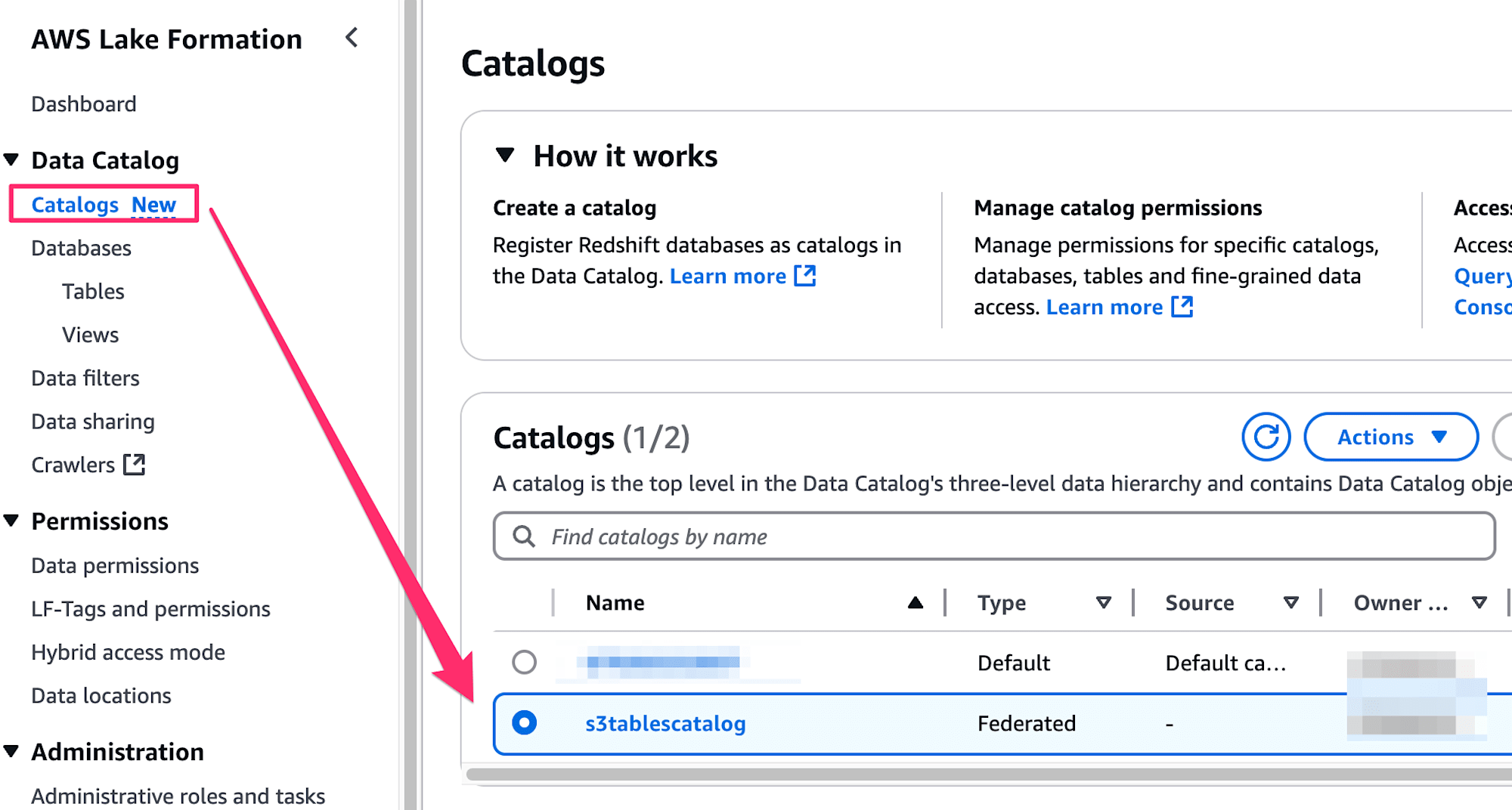
Action→Grantから利用しているIAMロールにs3tablesbucketへの権限を付与します。今回はSuper user権限を付与しました。
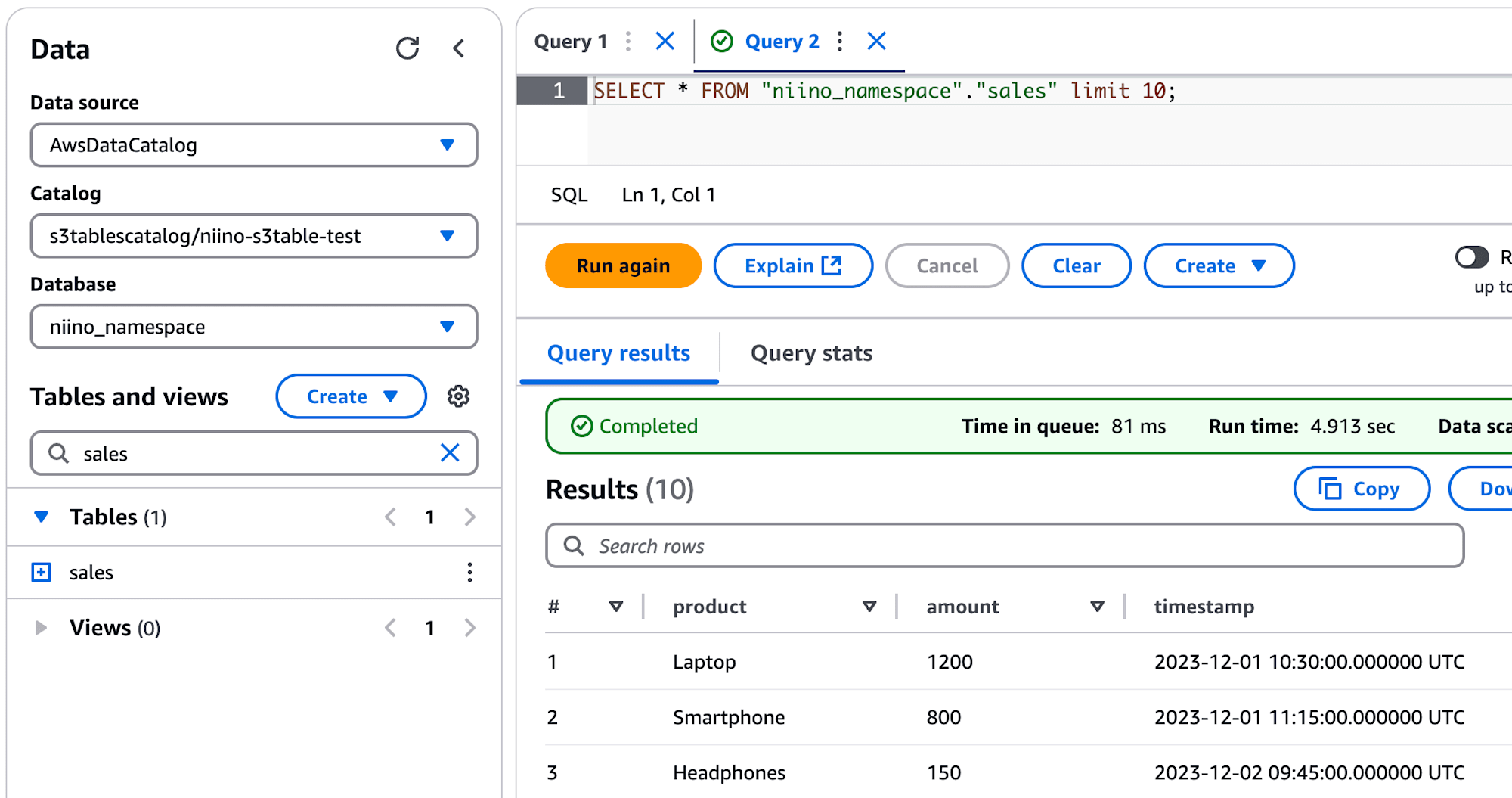
Athenaからcatalogにs3tablescatalog/<S3 Table名>を指定し、先ほど作成したテーブルがSELECTできるようになりました。
メンテナンス機能
ここまででIcebergテーブルを作成できることを確認しました。しかし、Icebergテーブルを効率的に運用するためには定期的なメンテナンスが必要です。具体的にはVACUUMとOPTIMIZEといったコマンドを実行する必要があります。
S3 Tableでは、これらのメンテナンス機能がデフォルトで有効化されています。メンテナンス機能は2つのレベルに分かれています:
- テーブルバケットレベル
- テーブルレベル
それぞれのレベルで利用できる機能が異なります。
参照されていない孤立ファイルの削除(テーブルバケットレベル)
テーブルから参照されず、unreferencedDaysプロパティで指定した日数より古いオブジェクトをNoncurrent状態に設定します。Noncurrent状態のオブジェクトは、nonCurrentDaysプロパティで指定された日数経過後削除されます。
-
デフォルト設定値
-
unreferencedDays: 3
-
nonCurrentDays: 10
-
-
実行に必要な権限
s3tables:PutTableBucketMaintenanceConfiguration
get-table-bucket-maintenance-configurationコマンドで以下の通り設定値を確認可能です。
$ aws s3tables get-table-bucket-maintenance-configuration --table-bucket-arn="<Table bucketのARN>"
{
"tableBucketARN": "<テーブルのARN>",
"configuration": {
"icebergUnreferencedFileRemoval": {
"status": "enabled",
"settings": {
"icebergUnreferencedFileRemoval": {
"unreferencedDays": 3,
"nonCurrentDays": 10
}
}
}
}
}
参考:
コンパクション(テーブルレベル)
データアクセスパターンに最適なターゲットファイルサイズ、もしくは指定した値に基づいてテーブルを圧縮します。コンパクションされたファイルはテーブルの最新のスナップショットとして書き込まれます。
-
デフォルト設定値
- targetFileSizeMB:512MB
-
実行に必要な権限
s3tables:GetTableMaintenanceConfigurations3tables:PutTableMaintenanceConfiguration
スナップショット管理(テーブルレベル)
テーブルスナップショットの有効期限を過ぎたオブジェクトを削除します。最小スナップショット数と スナップショットの最大有効時間に基づいて有効なスナップショット数を決定します。
-
デフォルト設定値
- minSnapshotsToKeep(最小スナップショット数): 1
- maxSnapshotAgeHours(スナップショットの最大有効時間): 120
-
実行に必要な権限(コンパクションと同一)
s3tables:GetTableMaintenanceConfigurations3tables:PutTableMaintenanceConfiguration
上記二つのテーブルレベルのメンテナンス設定内容はaws s3tables get-table-maintenance-configurationコマンドから確認可能です。put-table-maintenance-configurationコマンドから設定内容の変更・非有効化も可能です。
$ aws s3tables get-table-maintenance-configuration \
> --table-bucket-arn="<Table bucketのARN>" \
> --namespace="<Namespace名>" \
> --name="<テーブル名>"
{
"tableARN": "<テーブルのARN>",
"configuration": {
"icebergCompaction": {
"status": "enabled",
"settings": {
"icebergCompaction": {
"targetFileSizeMB": 512
}
}
},
"icebergSnapshotManagement": {
"status": "enabled",
"settings": {
"icebergSnapshotManagement": {
"minSnapshotsToKeep": 1,
"maxSnapshotAgeHours": 120
}
}
}
}
}
参考:
料金
料金は以下の3つの要素で構成されています。
- ストレージ使用料
- リクエスト料金
- テーブルバケットに保存された各オブジェクトに対するオブジェクトモニタリング
上述した通り、テーブルバケットには自動メンテナンス機能が備わっています。デフォルトで有効なコンパクション機能を使用すると以下に応じて料金が発生します。
- 処理対象となったオブジェクトの数
- 処理されたデータ量(バイト)
ストレージ料金
| 使用量 | 料金 |
|---|---|
| モニタリング料金(全ストレージ/月) | $0.025/1,000オブジェクト |
| 最初の50TB/月 | $0.0265/GB |
| 次の450TB/月 | $0.0253/GB |
| 500TB超/月 | $0.0242/GB |
リクエスト料金
| リクエストタイプ | 料金(1,000リクエストあたり) |
|---|---|
| PUT, COPY, POST, LIST | $0.005 |
| GET, SELECT, その他 | $0.0004 |
メンテナンス料金(コンパクション)
コンパクション料金は、テーブルバケット内のオブジェクトが自動コンパクション処理される際に発生します。テーブルバケット内の特定のテーブルで自動コンパクションを無効化するとこれらの料金は発生しません。
| 項目 | 料金 |
|---|---|
| オブジェクト処理 | $0.004/1,000オブジェクト |
| データ処理 | $0.05/GB |
参考:
(おまけ)CloudShellにSparkシェルをインストールする
EMRを使わずに気軽にテーブル作成を実施したい方向けのおまけです。
以下を参考にインストールを進めます。
以下コマンドでJDKをインストールします。
sudo yum install java-devel
次にApache Sparkをダウンロードします。今回は2024年12月現在の最新バージョンである3.5.3を取得しています。もし404: Not Found.エラーが出た場合はApache Sparkの公式サイトにアクセスして最新バージョンを確認してみてください。
wget https://dlcdn.apache.org/spark/spark-3.5.3/spark-3.5.3-bin-hadoop3.tgz
ダウンロードが完了したらパッケージを展開します。
tar xvf spark-3.5.3-bin-hadoop3.tgz
展開したSparkディレクトリを任意のディレクトリへ移動させます。
sudo mv spark-3.5.3-bin-hadoop3 <任意のディレクトリ>
次に環境変数を設定します。以下のコマンドから.bashrcファイルを開きます。
nano ~/.bashrc
以下の通り環境変数をファイル名で設定します。設定後、ctrl+x+Yで保存します。
export SPARK_HOME=<任意のディレクトリ>
export PATH=$PATH:$SPARK_HOME/bin
以下コマンドで.bashrcファイルをリロードします。
source ~/.bashrc
spark-shell --versionコマンドを実行すると、以下のようにSparkシェルのインストールが確認できました。
$ spark-shell --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.3
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 23.0.1
Branch HEAD
Compiled by user haejoon.lee on 2024-09-09T05:20:05Z
Revision 32232e9ed33bb16b93ad58cfde8b82e0f07c0970
Url https://github.com/apache/spark
Type --help for more information.
最後に
Apache Iceberg形式のテーブルデータに最適化されたストレージサービス、Amazon S3 Tablesのアップデートをご紹介しました。従来のテーブルフォーマットと異なり、データウェアハウスのような柔軟なテーブル操作を可能にしたIcebergはデータレイクの強力な選択肢となっています。一方で定期的なメンテナンスが必要とされ、VACUUMやOPTIMIZEクエリをStep Functionsから定期的に実行させるケースもありました。S3 Tableではテーブルを作ればコンパクションなどのメンテナンス機能がデフォルトで有効化され、自動で実行してくれるのはありがたいポイントです。
近頃のアップデートではIcebergを活用する機能が続々発表されており、データレイクをより便利に使えるように進化しています。今回はSparkを使ってテーブル操作を実施していますが、現段階ではプレビューのAthena連携が整って気軽にSQLを発行できるようになるともっと便利に使えそうです。
参照
あわせて読みたい










